DocuMind (Insight Garden)
A full-stack document RAG SaaS: upload PDFs, analyse them with AI, and chat with your documents via streaming answers—with source attribution and no hallucinations.
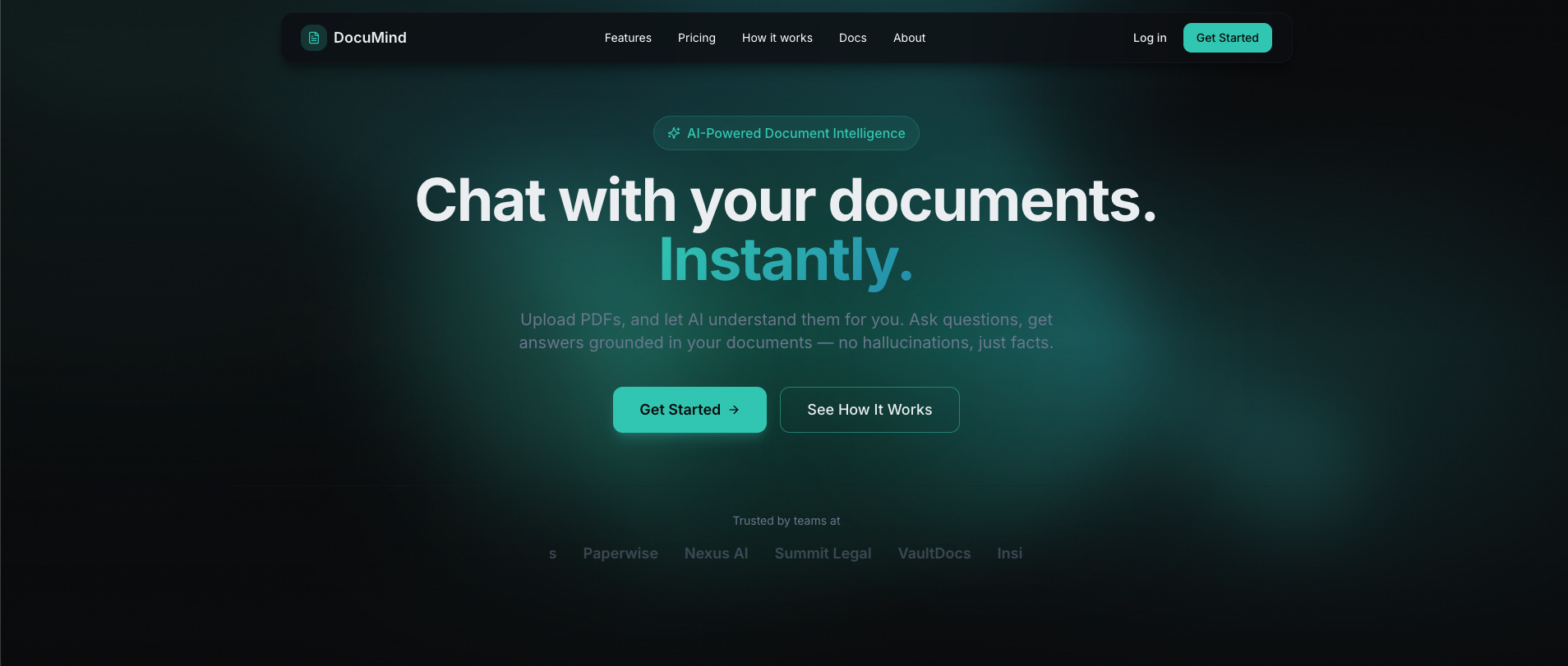
In a nutshell
- Full-stack document RAG: users upload PDFs, the system chunks and embeds them for analysis; users then query and analyse their documents via streaming AI—with source attribution.
- User auth (JWT), document upload (drag-and-drop, 50MB), async processing with progress, and per-document chat to analyse content with optional “show sources.”
- Hybrid retrieval (pgvector + lexical), configurable LLM/embedding providers (Ollama, OpenAI, Gemini, stub). SSE streaming for chat; frontend polls for processing status.
- Deployed: frontend on Vercel, backend on Railway, database on Supabase, Redis on Upstash.
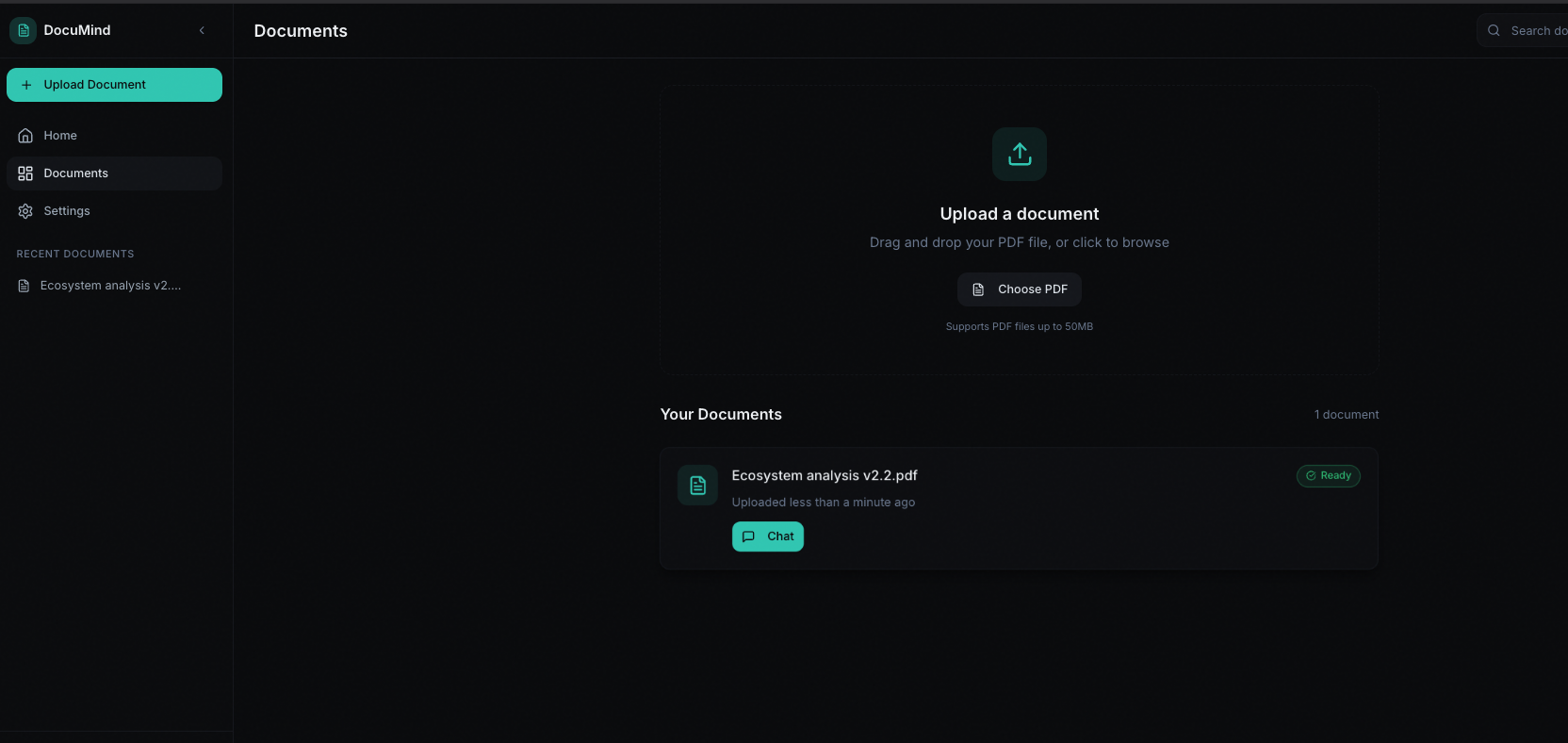
In the app
Sign in, upload your PDFs, and analyse them in under a minute—processing runs in the background so you can start chatting as soon as a document is ready.
What it is
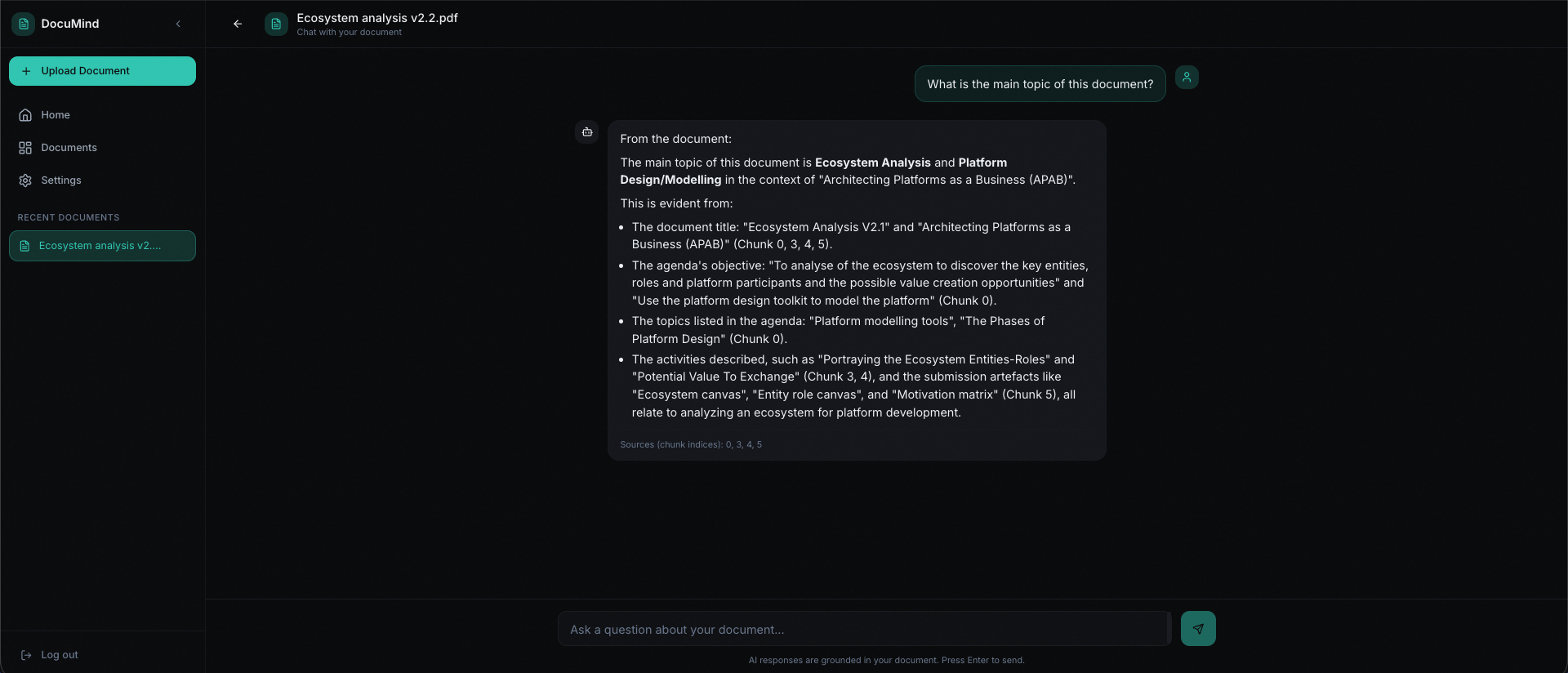
DocuMind turns your PDFs into a conversation. Upload, wait for processing, then ask questions and analyse your documents. Answers come only from your documents—no guesswork, no external leakage.
DocuMind is a document RAG (Retrieval-Augmented Generation) app. Users sign up, upload PDFs, and analyse and chat with their documents. The system chunks and embeds each PDF into a vector database; when you ask a question, it finds the relevant bits, builds a grounded prompt, and streams the answer back. You can toggle “show sources” to see which chunks and scores backed the reply.
I built it to show how a real RAG product hangs together end-to-end: auth, upload, async processing, progress feedback, and streaming chat—with clear ownership of data and configurable AI providers. The value proposition is simple: ask questions to your documents; get grounded, source-based answers. No hallucinations, no pulling from the open web.
What it does for users
Register and log in, upload PDFs (drag-and-drop or picker), watch processing progress, then analyse and chat per document with optional source citations.
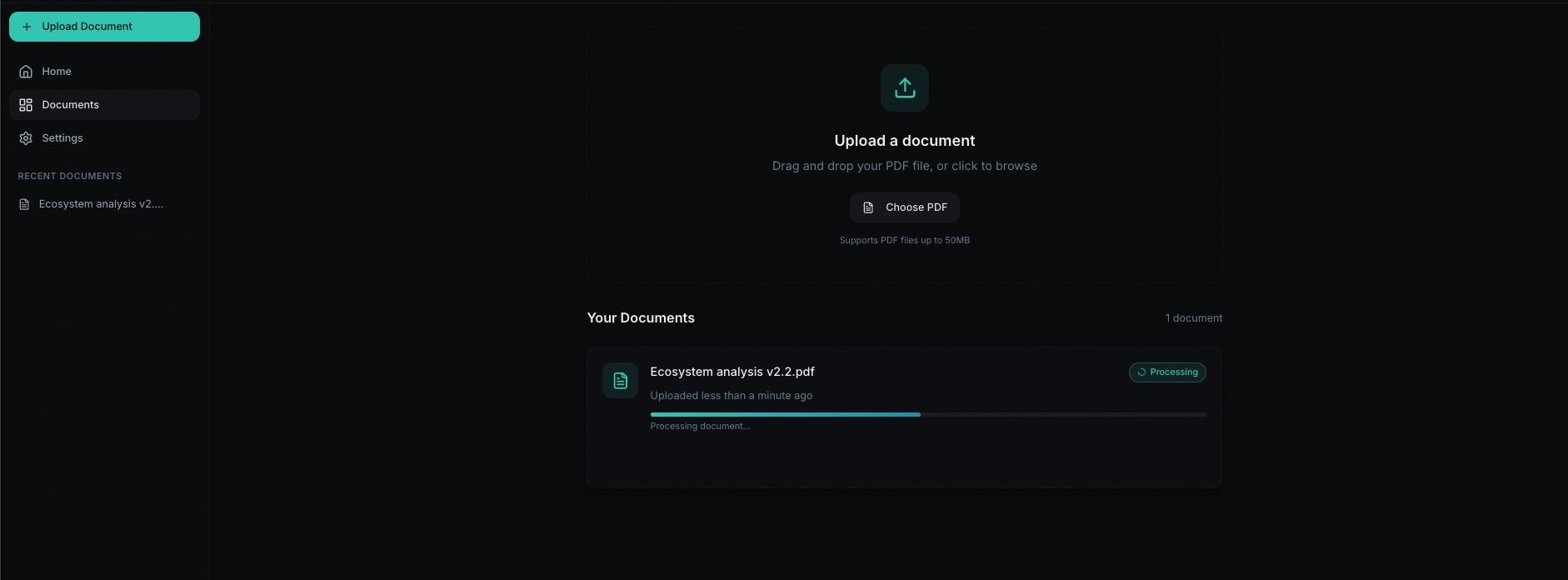
Users get auth (register/login with JWT, optional persistence and protected routes so the app doesn’t flash logged-out content). They get document upload via drag-and-drop or file picker, with a 50MB limit and server-side checks. Processing runs in the background: BullMQ + Redis job queue, PDF → text → chunk → embed → store in PostgreSQL with pgvector. The UI polls every couple of seconds and shows a progress bar and status (PENDING → PROCESSING → DONE or FAILED).
Once a document is ready, users open per-document chat to analyse it. They type a question; the backend embeds it, does hybrid retrieval (dense vectors + lexical search), builds a RAG prompt, and streams the answer over SSE. They can turn on “show sources” to see which chunks and scores were used. Settings let them tweak things like auto-scroll, show sources, and animations; account and system info (backend URL, version) are available where it makes sense. Health checks and clear error handling cover auth, network, and API failures so the app stays predictable in production.
How it’s built
React (Vite, TypeScript, Zustand, shadcn/ui) on the front end; NestJS (Prisma, pgvector, BullMQ, Redis) on the back. Streaming chat over SSE; progress via polling.
The front end is a React SPA: Vite 5, TypeScript 5, React 18, React Router 6 for public
and protected routes. State lives in Zustand (auth, documents, conversations, UI preferences), with
persistence for auth and prefs and a hydration gate so protected routes don’t flash before the app knows
if you’re logged in. Styling is Tailwind and shadcn/ui (Radix); animations use Framer Motion with
reduced-motion support. Chat streams via native fetch and ReadableStream;
forms use React Hook Form and Zod; markdown in chat is react-markdown.
The back end is NestJS 11 on Node (TypeScript 5): REST for most APIs, SSE for
/documents/:id/chat/stream. Auth is JWT (Passport + passport-jwt), passwords hashed with
bcrypt; a global JWT guard plus @Public() for auth and health. Validation is
class-validator/class-transformer with a global ValidationPipe. Data lives in PostgreSQL with Prisma 7;
vectors in pgvector (raw SQL for the vector column). Document processing jobs run in BullMQ with Redis;
PDF text comes from pdf-parse. Embeddings and LLM are configurable (stub or OpenAI for embeddings; stub,
Ollama, OpenAI, or Gemini for the LLM), so the same RAG pipeline can swap providers via env.
Flow: Upload hits POST /documents/upload; the backend creates a Document
(PENDING), stores the file, and enqueues a job. The worker extracts text, chunks (e.g. 900 chars, 100
overlap), embeds, and writes to document_chunks with progress (0 → 30 → 30–90 → 100). The
front end polls GET /documents/:id and shows status. For chat, the client calls
POST /documents/:id/chat/stream with { question }; the backend checks
ownership and DONE status, embeds the question, runs hybrid retrieval (pgvector + lexical), builds the
RAG prompt, and streams tokens over SSE with delta and done (and optional
sources).
Where it runs
Frontend on Vercel, backend on Railway, database on Supabase, Redis on Upstash. Split stack, env-driven config.
The app is deployed as a split stack: the React app on Vercel (with
VITE_API_URL pointing at the backend), the NestJS API on Railway,
PostgreSQL + pgvector on Supabase, and Redis (BullMQ) on Upstash.
CORS, env vars, and runtime config for the production API URL are documented so the front end always
talks to the right backend. Local dev uses Docker for Postgres and Redis; full deployment steps and
sanity checks live in the repo docs.
Standout technical choices
SSE with POST + Bearer auth, hybrid retrieval, protected routes that wait for hydration, and configurable LLM/embeddings so the pipeline isn’t tied to one vendor.
Streaming chat with POST and auth. Chat uses fetch +
ReadableStream, not EventSource, so the request can be a POST with a JSON body and
Authorization: Bearer. The backend supports ?token= for proxies where needed.
The client aborts the stream on logout or unmount so there are no dangling connections.
Hybrid retrieval. Answers are grounded in both dense (pgvector) and lexical (keyword) retrieval, merged and re-ranked. That often beats pure vector search for mixed query types and keeps relevance high.
Protected routes and hydration. The front end waits for Zustand persistence to hydrate before deciding whether to show the app or redirect to login. That avoids the flash of dashboard content for unauthenticated users.
Configurable LLM and embeddings. Stub, Ollama, OpenAI, and Gemini plug into the same RAG pipeline; embeddings can be stub or OpenAI. Swap via env—no code change for trying a new model.
Progress and status. Document processing reports numeric progress (0 → 30 → 30–90 → 100) and status (PENDING → PROCESSING → DONE/FAILED). The UI polls and shows a progress bar; when a document is DONE, users can go straight to chat.
What I implemented
End-to-end: auth, documents (upload, CRUD, processing jobs), chunks with pgvector, embedding and RAG modules, hybrid retrieval, SSE streaming, health checks, and a React app with dashboard, chat, and settings.
On the back end: Auth (register/login, JWT, bcrypt, DTOs, startup validation of JWT
secret). Documents (upload with Multer, CRUD, ownership checks, status and progress). Chunks
(insert/delete, raw SQL for pgvector). Embedding module (single interface: stub or OpenAI). Retrieval
service (hybrid pgvector + lexical, merge and re-rank, ownership and DONE enforcement). RAG module
(prompt building, LLM service with stub/Ollama/OpenAI/Gemini, streaming and non-streaming, latency
logging). Jobs module (BullMQ processor: PDF → text → chunk → embed → store; progress updates). Health
(GET /health). Common pieces: @Public(), @CurrentUser(), global
exception filter, CORS and ValidationPipe. SSE stream endpoint with Bearer (and optional query) auth and
abort on client disconnect.
On the front end: Public routes (landing, login, register, features, pricing, docs,
about, how-it-works, privacy, terms, contact) and protected routes (/app dashboard and
settings, /chat/:documentId) with ProtectedRoute and hydration-aware redirect.
Auth flow (login/register, API integration, Zustand with persistence, token in headers and for SSE).
Documents (dashboard list, upload with drag-and-drop and file picker, progress polling, errors). Chat
(per-document messages, user/assistant, markdown, sources; streaming via streamChat() with
delta/done parsing; typing indicator; optional auto-scroll; abort on unmount/logout). Settings (account,
preferences like auto-scroll and show sources, system info; persisted prefs). Landing (hero, features,
CTA, footer, navbar; Framer Motion and bubble background; reduced-motion hook). App shell (layout,
sidebar, header, backend health banner, runtime config for API URL). Error handling across auth, API,
and SSE.
What I learned
RAG is a system design problem. Retrieval quality drives answer quality more than the LLM. SSE with POST + auth is doable and keeps the API clean. Hybrid retrieval and progress UX make the product feel solid.
RAG isn’t just “retrieval plus generation”—it’s an architecture. If retrieval is weak, even a strong LLM will underperform. Get chunking, embeddings, and hybrid search right, and a simpler model can still deliver good, grounded answers. I learned to treat retrieval as a first-class subsystem: ownership checks, DONE enforcement, and re-ranking all matter.
Streaming chat over SSE with POST and Bearer auth was a deliberate choice. It keeps the API RESTful (one streaming endpoint, clear semantics) and avoids the limits of EventSource. Handling abort on unmount and logout keeps the client and server in sync.
Hybrid retrieval (dense + lexical) improved relevance over vector-only search, especially for exact terms and mixed queries. Letting users see sources (chunk indices and scores) built trust and made debugging easier.
Making LLM and embedding providers configurable meant I could test with stubs, run locally with Ollama, and switch to OpenAI or Gemini for production without rewriting the pipeline. That replaceability is something I’ll carry into other AI projects.
System Architecture
The full request lifecycle — from a user uploading a PDF to receiving a streamed, source-attributed answer — passes through five distinct layers. Each is independently replaceable via environment configuration.
DocuMind RAG pipeline — ingestion (left path) and chat retrieval (right path) share the same pgvector store. LLM and embedding providers are swappable via environment variables.
Key Metrics
- Streaming chat responses via SSE — POST endpoint with Bearer auth, no EventSource limitations
- Hybrid retrieval combining dense pgvector cosine search and lexical keyword matching, with merge and re-rank
- Asynchronous ingestion pipeline — BullMQ workers report numeric progress (0 → 30 → 30–90 → 100) so users see live status
- Configurable LLM providers (stub / Ollama / OpenAI / Gemini) and embedding providers — swap via environment variable, no code change
- Split-stack deployment: React on Vercel, NestJS on Railway, PostgreSQL + pgvector on Supabase, Redis on Upstash
- JWT auth with bcrypt password hashing, global JWT guard, and hydration-aware protected routes to prevent unauthenticated flashes
- Chunk size: 900 characters with 100-character overlap — single config drives both training-time chunking and inference
Portfolio one-liner
DocuMind (Insight Garden) — Full-stack document RAG SaaS: React (Vite, TypeScript, Zustand, shadcn/ui) + NestJS (Prisma, pgvector, BullMQ, Redis). Users upload PDFs; async jobs chunk and embed into PostgreSQL/pgvector; hybrid retrieval + configurable LLM power streaming chat with source attribution. Deployed: frontend on Vercel, backend on Railway, database on Supabase, Redis on Upstash. JWT auth, protected routes, SSE streaming, health and error handling throughout.